It’s well known that DNA Sequence is a sequence only contains A, C, T and G, and it’s very useful to analyze a segment of DNA Sequence. For example, if a animal’s DNA sequence contains segment ATC then it may mean that the animal may have a genetic disease. Until now scientists have found several those segments, the problem is how many kinds of DNA sequences of a species don’t contain those segments.
Suppose that DNA sequences of a species is a sequence that consist of A, C, T and G, and the length of sequences is a given integer n.
Input
First line contains two integer m (0≤m≤10), n (1≤n≤2000000000). Here, m is the number of genetic disease segment, and n is the length of sequences.
Next m lines each line contain a DNA genetic disease segment, and length of these segments is not larger than 10.
Output
An integer, the number of DNA sequences, mod100000.
Sample Input
1 2 3 4 5
4 3 AT AC AG AA
Sample Output
1
36
Idea
设字典树可接受字符集为小写英文字母。将 m 个病毒串插入字典树,并为病毒串末尾打上标记。我们的目标是,从树根出发,走 n 层构造出一个字符串 s,且 s 的任意子串都不是病毒串。
上述方法存在两个问题。第一,我们仅仅在字典树上插入了病毒串,若要使得构造的字符串 s 能够使用字符集中的所有字母,需要存一棵 26 叉树,这显然是不可能的。第二,如果我们仅仅在病毒串的结尾打标记,会对病毒串的检索遗漏,比如插入两个字符串 ACG 和 C,我们在两个字符串的结尾 G 和 C 打上标记;然而,若游走到了树上表示 AC 的位置,实际上已经包含病毒串 C,但是我们并没有在这个位置打上标记。
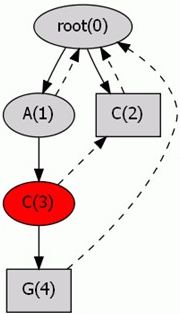
对于上述两个问题,在字典树的基础上构建AC自动机就可以解决。在构建AC自动机时,对于指向空的状态转移 trie(u,i),不再为其分配结点,而是将其指向 trie(failu,i),达到了路径压缩的目的,由于 failu 指针指向了 u 的后缀,我们可以理解为省略了 u 的前缀而继续向下寻找;同时 fail 指针具有良好的性质,failu 指向的字符串是 u 表示的字符串的最长可匹配后缀,因此若 failu 被打上标记,则 u 也应当打上标记。
图的邻接矩阵 A,Aijn 代表在图上从 i 出发走 n 步到达 j 的路径数量。我们可构造AC自动机上的邻接矩阵:若 trie(i,j) 没有被打上标记,则 Ai,trie(i,j)=0,否则 Ai,trie(i,j) 增加 1。在此说明为什么是 Ai,trie(i,j) 增加 1,而不是令 Ai,trie(i,j)=1:因为AC自动机在构建 fail 指针的过程中顺带完成了路径压缩的工作,会有多条边指向 trie(i,j)。
在AC自动机上游走 n 步,i=0∑totA0,in 即为答案,tot 为AC自动机上最大点的编号,树根编号为 0。

 微信
微信 支付宝
支付宝 QQ
QQ