匈牙利算法
二分图最大匹配
二分图
二分图又称作二部图,是图论中的一种特殊模型。 设 是一个无向图,如果顶点 可分割为两个互不相交的子集 ,并且图中的每条边 所关联的两个顶点和分别属于这两个不同的顶点集,则称图 为一个二分图。

判定定理:无向图G为二分图的充分必要条件是,G至少有两个顶点,且其所有回路的长度均为偶数。
最大匹配
给定一个二分图 ,在 的一个子图 中, 的边集中的任意两条边都不依附于同一个顶点,则称 是一个匹配。所有匹配组成的集合中,边数最大的子集称为图的最大匹配。
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
增广路径
给定图 的一个匹配 ,如果一条路径的边 交替出现 和 的情况,我们称之为一条 交错路径。而如果一条 交错路径,它的两个端点都不与 中的边关联,我们称这条路径叫做 增广路径。

如上图,边集 $\{2,4\}$ 是一个匹配,于是 $\{1,2,3,4,5\}$ 是一条交错路径,且该路径的两个端点不与匹配 关联,所以 $\{1,2,3,4,5\}$ 还是一条 增广路径。
设 为一条 增广路径,则:
- 的路径长度必定为奇数,第一条边和最后一条边都不属于;
- 经过取反操作可以得到一个更大的匹配 ;
- 为 的最大匹配当且仅当不存在相对于 的增广路径。
匈牙利算法原理
寻找增广路径
如上图,边集 $\{2,4\}$ 是一个匹配,$\{1,2,3,4,5\}$ 是一条 增广路径。
毫无疑问,边集 $\{1,3,5\}$ 也是一个匹配,而这个匹配比原先的匹配 多一条边,是一个比原先 更大的匹配。
寻找最大匹配的任务就相当于在已经确定的匹配下,不断找到新的增广路径,因为出现一条增广路径,就意味着目前的匹配中增加一条边。
算法轮廓
①置 为空;
②找出一条增广路径 ,通过取反操作获得更大的匹配 代替 ;
③重复②操作直到找不出增广路径为止。
过程模拟
初始二分图如下
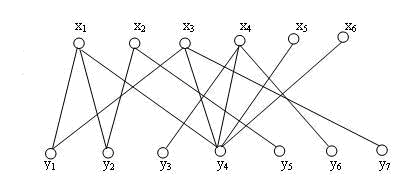
①随意选取一条边,比如这条边,构建最初的匹配。
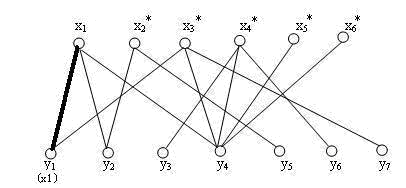
②给添加一个匹配,添加边。
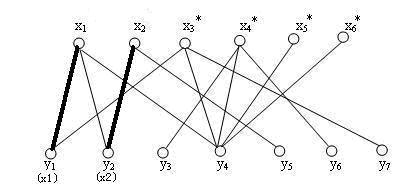
③现在要给匹配一条边,发现它的另一端已经被占用了,于是与脱离,让与相连。开始寻找新的匹配,因为 与相连,于是与脱离,让与相连。找到与之相连。
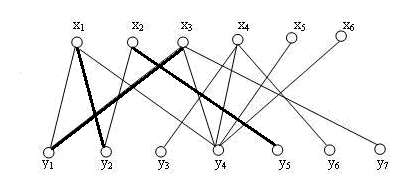
上述的过程可以称作一种协商的形式,每一个点进行配对时,如果目标的连接点已经被连接,就需要进行协商操作,使得目标点产生空缺。上述过程中的节点可组成点集 $\{x_3, y_1, x_1, y_2, x_2, y_5\}$,形成一条路径 。
在步骤②中,已经形成了匹配 , 实际上是一条 增广路径。
发现一条增广路径,就意味着一个更大匹配的出现。于是,我们将 中的配对点拆分开,重新组合,得到了一个更大匹配, 其拥有 三条边。
同样, 按顺序加入进来,最终会得到这个二分图的最大匹配。
注意:最大匹配不唯一,最大匹配数是唯一的。
时间复杂度
邻接矩阵,邻接表。
模板题
POJ 3041 Asteroids
Description
Bessie wants to navigate her spaceship through a dangerous asteroid field in the shape of an grid . The grid contains asteroids , which are conveniently located at the lattice points of the grid.
Fortunately, Bessie has a powerful weapon that can vaporize all the asteroids in any given row or column of the grid with a single shot. This weapon is quite expensive, so she wishes to use it sparingly. Given the location of all the asteroids in the field, find the minimum number of shots Bessie needs to fire to eliminate all of the asteroids.
Input
Line 1: Two integers and , separated by a single space.
Lines 2…K+1: Each line contains two space-separated integers and denoting the row and column coordinates of an asteroid, respectively.
Output
Line 1: The integer representing the minimum number of times Bessie must shoot.
Sample Input
3 4
1 1
1 3
2 2
3 2
Sample Output
2
Hint
INPUT DETAILS
The following diagram represents the data, where “X” is an asteroid and “.” is empty space:
X.X
.X.
.X.
OUTPUT DETAILS
Bessie may fire across row to destroy the asteroids at and , and then she may fire down column to destroy the asteroids at and .
Translation
一个飞船在的网格里面飞,网格里有障碍,一个子弹可以打穿一行或者一列,求消除所有障碍的最少子弹。
Idea
将行坐标看作一个集合,列坐标看作一个集合,形成一张二分图,每个点就连接两个集合的边,求出最大匹配就是所要的答案。
有定理:二分图最小点覆盖等于二分图最大匹配。
这是两个集合中点的个数相同的二分图匹配。
Code
1 |
|
HDU 1083 Courses
Problem Description
Consider a group of students and courses. Each student visits zero, one or more than one courses. Your task is to determine whether it is possible to form a committee of exactly students that satisfies simultaneously the conditions:
- every student in the committee represents a different course (a student can represent a course if he/she visits that course)
- each course has a representative in the committee
Input
Your program should read sets of data from a text file. The first line of the input file contains the number of the data sets. Each data set is presented in the following format:
$Student_{12} $$\dots$
$Student_{22} $$\dots$
…
$Student_{P2} $$\dots$
The first line in each data set contains two positive integers separated by one blank: - the number of courses and - the number of students. The next lines describe in sequence of the courses from course to course , each line describing a course. The description of course is a line that starts with an integer representing the number of students visiting course . Next, after a blank, you’ll find the students, visiting the course, each two consecutive separated by one blank. Students are numbered with the positive integers from to .
There are no blank lines between consecutive sets of data. Input data are correct.
Output
The result of the program is on the standard output. For each input data set the program prints on a single line “YES” if it is possible to form a committee and “NO” otherwise. There should not be any leading blanks at the start of the line.
Sample Input
2
3 3
3 1 2 3
2 1 2
1 1
3 3
2 1 3
2 1 3
1 1
Sample Output
YES
NO
Translation
一共有 门课,每门课都有若干的学生,现在要为每个课程选一名课代表,每个学生只能担任一门课的课代表,如果每个课都能找到课代表,则输出"YES",否则"NO"。
Idea
二分图最大匹配,对课程—学生关系建立一个二分图,进行二分图的最大匹配。如果最大匹配数与课程数相等,说明能够满足要求,否则不能。
和前一题是几乎一模一样的板子,只是这里两个集合中点的个数不同。
Code
1 |
|
 微信
微信 支付宝
支付宝 QQ
QQ